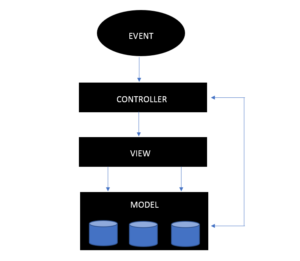
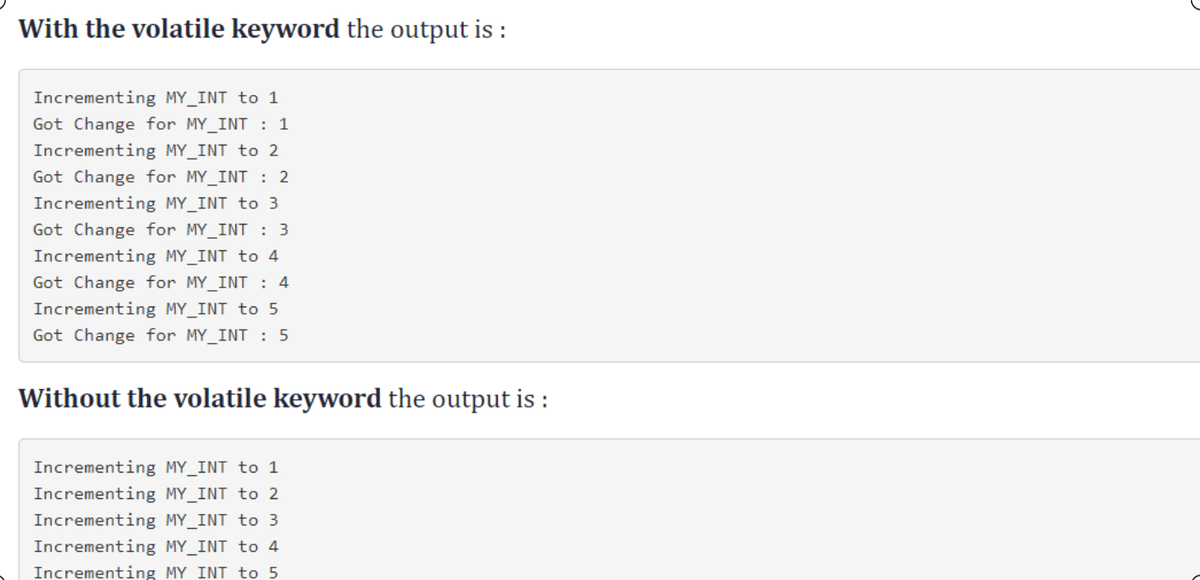
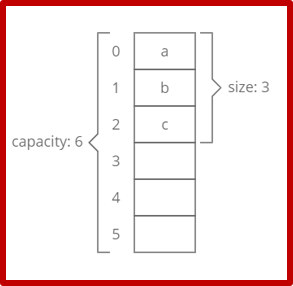
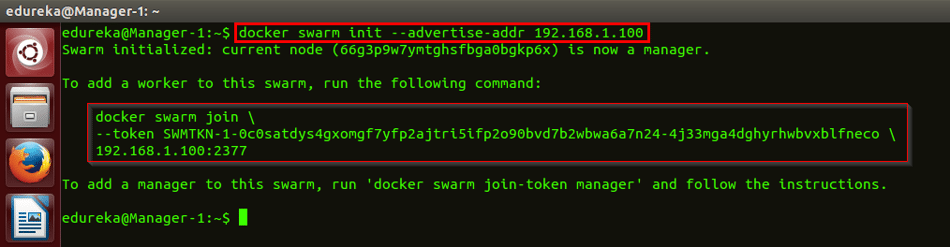
Trách nhiệm của quản trị viên Hadoop
Blog này về trách nhiệm của Quản trị viên Hadoop thảo luận về phạm vi quản lý Hadoop. Các công việc quản trị viên Hadoop đang có nhu cầu cao vì vậy hãy tìm hiểu Hadoop ngay bây giờ!

Blog này về trách nhiệm của Quản trị viên Hadoop thảo luận về phạm vi quản lý Hadoop. Các công việc quản trị viên Hadoop đang có nhu cầu cao vì vậy hãy tìm hiểu Hadoop ngay bây giờ!
Apache Spark là một bước phát triển vượt bậc trong lĩnh vực xử lý dữ liệu lớn.
Apache Hadoop 2.x bao gồm những cải tiến đáng kể so với Hadoop 1.x. Blog này nói về Liên đoàn kiến trúc cụm Hadoop 2.0 và các thành phần của nó.
Điều này cung cấp một cái nhìn sâu sắc về việc sử dụng Trình theo dõi công việc
Apache Pig có nhiều chức năng được xác định trước. Bài đăng chứa các bước rõ ràng để tạo UDF trong Apache Pig. Ở đây các mã được viết bằng Java và yêu cầu Thư viện lợn
Ở đó, kiến trúc lưu trữ HBase bao gồm nhiều thành phần. Hãy xem các chức năng của các thành phần này và biết cách dữ liệu đang được ghi.
Apache Hive là một gói Data Warehousing được xây dựng trên Hadoop và được sử dụng để phân tích dữ liệu. Hive được nhắm mục tiêu đến những người dùng thông thạo SQL.
Việc các công ty hàng đầu triển khai Apache Spark với Hadoop trên quy mô lớn cho thấy sự thành công và tiềm năng của nó khi xử lý thời gian thực.
Tính sẵn sàng cao của NameNode là một trong những tính năng quan trọng nhất của NameNode 2.0 Hadoop 2.0 với tính năng Quorum Journal Manager được sử dụng để chia sẻ nhật ký chỉnh sửa giữa NameNode đang hoạt động và dự phòng.
Trách nhiệm công việc của nhà phát triển Hadoop bao gồm nhiều nhiệm vụ. Trách nhiệm của công việc phụ thuộc vào miền / lĩnh vực của bạn. Vai trò này giống như một Nhà phát triển phần mềm
Mô hình dữ liệu Hive chứa các thành phần sau như Cơ sở dữ liệu, Bảng, Phân vùng và Nhóm hoặc cụm .ive hỗ trợ các kiểu nguyên thủy như Số nguyên, Pha nổi, Đôi và Chuỗi.
4 lý do để nâng cấp lên Hadoop 2.0 nói về thị trường việc làm Hadoop và cách nó có thể giúp bạn đẩy nhanh sự nghiệp bằng cách giúp bạn mở ra các cơ hội việc làm lớn.
Trong blog này, chúng tôi sẽ chạy các ví dụ về Hive và Yarn trên Spark. Đầu tiên, xây dựng Hive và Yarn trên Spark và sau đó bạn có thể chạy các ví dụ Hive và Yarn trên Spark.
Mục tiêu của blog này là tìm hiểu cách chuyển dữ liệu từ cơ sở dữ liệu SQL sang HDFS, cách chuyển dữ liệu từ cơ sở dữ liệu SQL sang cơ sở dữ liệu NoSQL.
Nhà phát triển được chứng nhận Cloudera cho Apache Hadoop (CCDH) là một sự thúc đẩy cho sự nghiệp của một người. Bài đăng này thảo luận về lợi ích, các mẫu kỳ thi, hướng dẫn học tập và các tài liệu tham khảo hữu ích.
Blog này cung cấp tổng quan về kiến trúc Tính khả dụng cao HDFS và cách thiết lập và định cấu hình cụm Tính khả dụng cao HDFS trong các bước đơn giản.
Apache Kafka tiếp tục được yêu thích khi nói đến Phân tích thời gian thực. Dưới đây là một cái nhìn về nó từ quan điểm nghề nghiệp, thảo luận về các cơ hội nghề nghiệp và nhu cầu công việc.
Apache Kafka cung cấp hệ thống nhắn tin có thông lượng cao và khả năng mở rộng khiến nó trở nên phổ biến trong phân tích thời gian thực. Tìm hiểu cách hướng dẫn Apache kafka có thể giúp bạn
Bài đăng trên blog này đi sâu vào Pig và các chức năng của nó. Bạn sẽ tìm thấy bản demo về cách bạn có thể làm việc trên Hadoop bằng Pig mà không phụ thuộc vào Java.
Blog này thảo luận về các điều kiện tiên quyết để học Hadoop, những điều cần thiết về Java cho Hadoop và câu trả lời 'bạn có cần Java để học Hadoop không' nếu bạn biết Pig, Hive, HDFS.