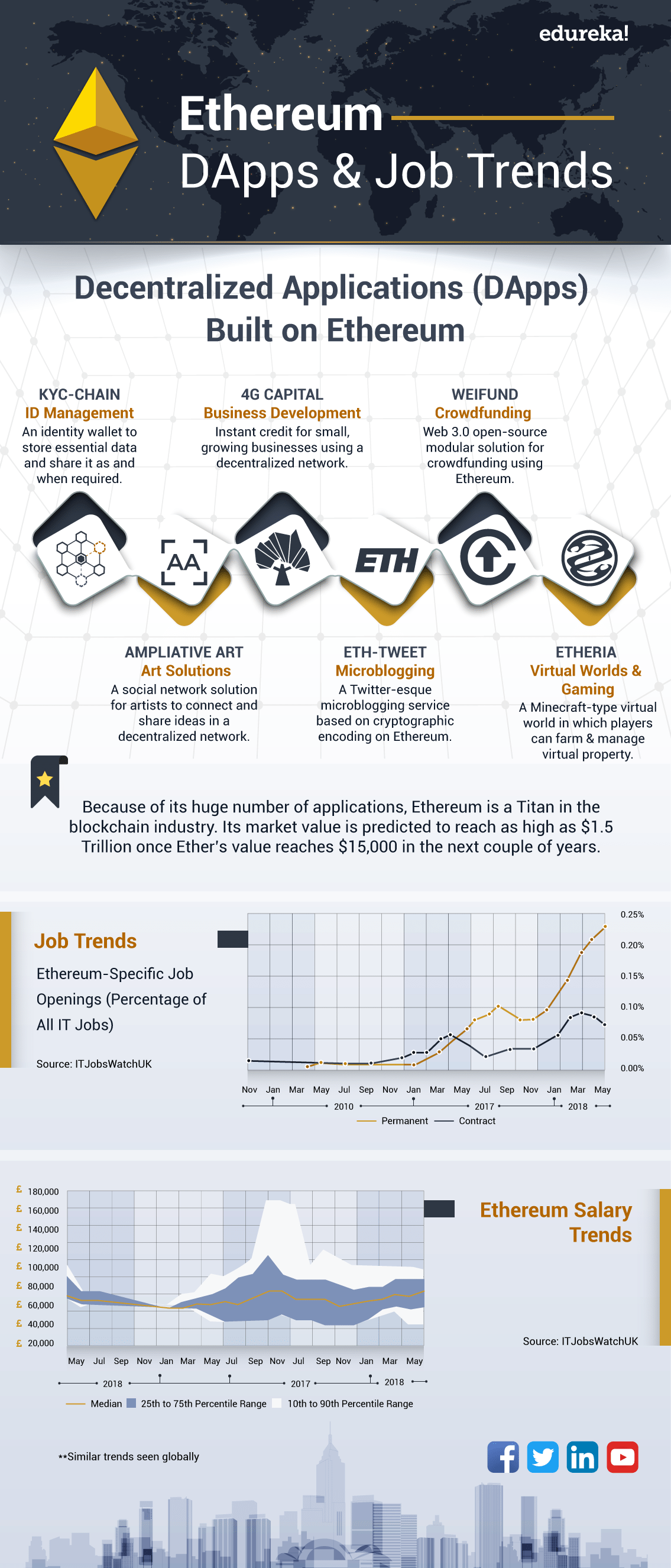
Spark vs Hadoop: Khung dữ liệu lớn nào tốt nhất?
Bài đăng trên blog này nói về apache spark vs hadoop. Nó sẽ cung cấp cho bạn ý tưởng về khung Dữ liệu lớn phù hợp để lựa chọn trong các tình huống khác nhau.

Bài đăng trên blog này nói về apache spark vs hadoop. Nó sẽ cung cấp cho bạn ý tưởng về khung Dữ liệu lớn phù hợp để lựa chọn trong các tình huống khác nhau.
Blog này giúp bạn hiểu cách cài đặt và thiết lập plugin sbteclipse với hướng dẫn từng bước để chạy ứng dụng Scala trong Eclipse IDE.
Bài đăng trên blog này giải thích tại sao bạn phải bắt đầu với Apache Spark sau khi sử dụng Hadoop và tại sao việc học Spark sau khi thành thạo hadoop có thể làm nên điều kỳ diệu cho sự nghiệp của bạn!
Hướng dẫn Apache Drill này cung cấp cho bạn tất cả thông tin bạn cần để bắt đầu với công cụ truy vấn Apache Drill, cách sử dụng với Hadoop, Big Data & Apache Spark.
Blog Spark Hadoop này cho bạn biết tất cả những gì bạn cần biết về Apache Spark kết hợpByKey. Tìm điểm trung bình của mỗi học sinh bằng cách sử dụng phương pháp connectByKey.
Apache Falcon là một nền tảng quản lý dữ liệu mới cho hệ sinh thái Hadoop giúp đơn giản hóa quá trình tích hợp nguồn cấp dữ liệu và quản lý nguồn cấp dữ liệu trên các cụm hadoop. Tìm hiểu cách thiết lập nó.
Blog Apache Spark này giải thích chi tiết về bộ tích lũy Spark. Tìm hiểu cách sử dụng bộ tích điện Spark với các ví dụ. Bộ tích lũy tia lửa giống như bộ đếm Hadoop Mapreduce.
Tìm hiểu tất cả về Apache Flink và thiết lập một cụm Flink trong blog này. Flink hỗ trợ thời gian thực & xử lý hàng loạt và là công nghệ Dữ liệu lớn phải xem cho Phân tích dữ liệu lớn.
Bài đăng trên blog này thảo luận về bộ nhớ đệm phân tán với các biến phát sóng và giúp bạn bắt đầu phân phối hiệu quả các giá trị lớn trong lập trình Spark.
Chứng chỉ CCA và CCP của Cloudera đã thay thế các kỳ thi CCDH và CCSHB. Blog này cho bạn biết tất cả những gì bạn cần biết về các chứng chỉ mới.
Bài đăng trên blog này thảo luận về các chuyển đổi trạng thái với cửa sổ trong Spark Streaming. Tìm hiểu tất cả về theo dõi dữ liệu theo lô bằng cách sử dụng D-Streams toàn trạng.
Bài đăng trên blog này thảo luận về các chuyển đổi trạng thái trong Spark Streaming. Tìm hiểu tất cả về theo dõi tích lũy và nâng cao kỹ năng cho sự nghiệp Hadoop Spark.
Công nghệ Hadoop & Big Data đang cách mạng hóa phân tích chăm sóc sức khỏe. Dữ liệu lớn trong blog chăm sóc sức khỏe này thảo luận về cách phân tích dữ liệu lớn có thể nâng cao hoạt động chăm sóc y tế.
Bài đăng blog này trên Hadoop Streaming là hướng dẫn từng bước để học cách viết một chương trình Hadoop MapReduce bằng Python để xử lý một lượng lớn Dữ liệu lớn.
Blog Hướng dẫn về Dữ liệu lớn này cung cấp cho bạn cái nhìn tổng quan đầy đủ về Dữ liệu lớn, các đặc điểm, ứng dụng của nó cũng như những thách thức với Dữ liệu lớn.
Blog Hướng dẫn HDFS này sẽ giúp bạn hiểu Hệ thống tệp phân tán HDFS hoặc Hadoop và các tính năng của nó. Bạn cũng sẽ khám phá tóm tắt các thành phần cốt lõi của nó.
Trong hướng dẫn Splunk này, hãy hiểu sự khác biệt giữa Splunk so với ELK và Sumo Logic và xác định công cụ nào trong số những công cụ này phù hợp với bạn nhất.
Trong blog trường hợp sử dụng Splunk này, bạn sẽ hiểu cách Domino's Pizza đã sử dụng Splunk để thu thập thông tin chi tiết về hành vi của người tiêu dùng và xây dựng chiến lược kinh doanh của họ.
Hướng dẫn này là hướng dẫn từng bước để cài đặt cụm Hadoop và định cấu hình nó trên một nút duy nhất. Tất cả các bước cài đặt Hadoop dành cho máy CentOS.
Blog này nói về các lệnh HDFS khác nhau như fsck, copyFromLocal, expunge, cat, v.v. được sử dụng để quản lý Hệ thống tệp Hadoop.